論文タイトルから雑誌名を当てるプヨグラムを書く
【イントロ】
名は体を表すということわざがあるように、名前というのは大切な個性です。
子供が生まれると、ご両親は画数や漢字の組み合わせなど、いろいろ思い悩んで最高の名前を子供につけてあげるという大きなイベントが待ち構えています[1]。(楽しそう
すこしでも明るい未来を歩んでほしいという親心に胸が熱くなりますね。
それでは、研究者にとっていちばん大切な子供である論文にはどのような名前をつけて上げれば、輝かしい未来が待っているのでしょうか?
そこで今回は、論文のタイトルから掲載されている論文誌を予測する方法がないか考えてみることにしました。
【方法】
ほんとは”きかい学習”とか”でぃーぷらーにんぐ”とかかっこいい手段を使いたいのですが、知性が足りないので露骨な力技を採用することにしました。
「各論文誌の出現単語数を頻度順に並べ、頻度が高いものから順にポイントを与え、予測したいタイトルに含まれる単語の総ポイントを各論文誌毎に計算し、最もポイントが高くなる論文誌が一番”それっぽい”論文誌と判断する」、というアルゴリズムにしました。
今回対象としたのは物理学における定番論文誌、APS発行のPhysical Review誌[2]です。
まず、Physical Review A, B, C, D, E, Lの各論文誌1年間の論文タイトルをWeb Scrapingにより取得します[3]。ここで注意すべきなのは取得間隔を十分にとることです。さもないとアクセス過多でアク禁されます。(反省)
ただし皆さんご存知かと思いますが、1年間待つことでアク禁が解除されます[4]。
APSは優しいですね。
つぎに、取得したタイトルを出現頻度順にならべます。そして、最多出現頻度を1として規格化します。すると、下図のようなcsvファイルが作成できます。これを各論文誌毎に用意します。
注意すべきなのは単語を大文字か小文字に揃えることです。
皆さんご存知かと思いますが、Phys.Rev.誌はPRLのみ論文タイトルの単語の頭文字すべてが大文字、PRA, B, C, D, Eは先頭の単語のみ大文字になっているという違いがあります。これに気づかないと、PRLだけ100%正答することになります。
わたしはこれで休日を1日潰しました。
次に、予測したい論文タイトルを集めます。これは最新論文から適当に25本ずつ集めました。論文誌6本で全150本です。
このタイトルを読み込み、単語に分割します。そして、各論文誌毎にポイントを計算します。このとき、未知の単語に対して何ポイント付与するかが問題ですが、とりあえずある程度負の値が良さそうです(霊感)。
そして、一番高いポイントを示した論文誌がその論文の掲載誌と判断しました。
こうして比較した全150本の論文のうち何本で正解したか示したのが下図です。
正解率53%。。。( ;`・~・) ぐぬぬ…当てずっぽうだと1/6=17%程度の正解率になるので、それを踏まえると割とマシな予測になっています。今はこれが限界。。。
【まとめ】
今回は、論文タイトルから掲載誌を予測するプログラムを書くことを目指しました。力づくで比較した結果として正解率53%を得ることができました。今後はもっと高度な技術を手に入れて再チャレンジしてみたいです。( ˘ω˘)スヤァ
【参考文献】
【設計図】
名は体を表すということわざがあるように、名前というのは大切な個性です。
子供が生まれると、ご両親は画数や漢字の組み合わせなど、いろいろ思い悩んで最高の名前を子供につけてあげるという大きなイベントが待ち構えています[1]。(楽しそう
すこしでも明るい未来を歩んでほしいという親心に胸が熱くなりますね。
それでは、研究者にとっていちばん大切な子供である論文にはどのような名前をつけて上げれば、輝かしい未来が待っているのでしょうか?
そこで今回は、論文のタイトルから掲載されている論文誌を予測する方法がないか考えてみることにしました。
【方法】
ほんとは”きかい学習”とか”でぃーぷらーにんぐ”とかかっこいい手段を使いたいのですが、知性が足りないので露骨な力技を採用することにしました。
「各論文誌の出現単語数を頻度順に並べ、頻度が高いものから順にポイントを与え、予測したいタイトルに含まれる単語の総ポイントを各論文誌毎に計算し、最もポイントが高くなる論文誌が一番”それっぽい”論文誌と判断する」、というアルゴリズムにしました。
今回対象としたのは物理学における定番論文誌、APS発行のPhysical Review誌[2]です。
まず、Physical Review A, B, C, D, E, Lの各論文誌1年間の論文タイトルをWeb Scrapingにより取得します[3]。ここで注意すべきなのは取得間隔を十分にとることです。さもないとアクセス過多でアク禁されます。(反省)
ただし皆さんご存知かと思いますが、1年間待つことでアク禁が解除されます[4]。
APSは優しいですね。
つぎに、取得したタイトルを出現頻度順にならべます。そして、最多出現頻度を1として規格化します。すると、下図のようなcsvファイルが作成できます。これを各論文誌毎に用意します。
注意すべきなのは単語を大文字か小文字に揃えることです。
皆さんご存知かと思いますが、Phys.Rev.誌はPRLのみ論文タイトルの単語の頭文字すべてが大文字、PRA, B, C, D, Eは先頭の単語のみ大文字になっているという違いがあります。これに気づかないと、PRLだけ100%正答することになります。
わたしはこれで休日を1日潰しました。
 |
| 図1,1年間の論文に含まれる単語の頻度。A列が単語、B列が規格化した出現数、C列が出現数。 |
次に、予測したい論文タイトルを集めます。これは最新論文から適当に25本ずつ集めました。論文誌6本で全150本です。
このタイトルを読み込み、単語に分割します。そして、各論文誌毎にポイントを計算します。このとき、未知の単語に対して何ポイント付与するかが問題ですが、とりあえずある程度負の値が良さそうです(霊感)。
そして、一番高いポイントを示した論文誌がその論文の掲載誌と判断しました。
こうして比較した全150本の論文のうち何本で正解したか示したのが下図です。
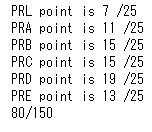 |
| 図2、各論文誌25本中、予測と実際が正解した数 |
正解率53%。。。( ;`・~・) ぐぬぬ…当てずっぽうだと1/6=17%程度の正解率になるので、それを踏まえると割とマシな予測になっています。今はこれが限界。。。
【まとめ】
今回は、論文タイトルから掲載誌を予測するプログラムを書くことを目指しました。力づくで比較した結果として正解率53%を得ることができました。今後はもっと高度な技術を手に入れて再チャレンジしてみたいです。( ˘ω˘)スヤァ
【参考文献】
- 姓名判断
- Physical Review誌
- 「2016-17年度フィジカルレビュー誌流行語調査...みたいな?」
- Private experience.
【設計図】
#!/usr/bin/python
# coding: UTF-8
import re
x=-10.0 #出てこない単語に対するポイント
def numA(title): #PRAのポイント計算
dict={}
f = open('PRAtitle.csv')#単語と出現頻度のファイル開く
data1 = f.readline() #各行を読み込む
while data1:#すべての行で繰り返す
lst=re.split('[,\n]', data1) #各行を,と\nで分割
dict[lst[0]]=float(lst[1]) #各単語=各頻度を辞書に保管
data1 = f.readline() #次の行を読み込む
f.close() #ファイルを閉じる
p=title.split()
#print(p)
t=0
for i in p:
r=dict.get(i,x)
t+=r
return t
def numB(title): #PRBのポイント計算
dict={} #ココのブロックで辞書の中身を作る
f = open('PRBtitle.csv')#単語と出現頻度のファイル開く
data1 = f.readline() #各行を読み込む
while data1:#すべての行で繰り返す
lst=re.split('[,\n]', data1) #各行を,と\nで分割
dict[lst[0]]=float(lst[1]) #各単語=各頻度を辞書に保管
data1 = f.readline() #次の行を読み込む
f.close() #ファイルを閉じる
p=title.split() #入力したタイトルをリストに分割
#print(p)
t=0
for i in p:
r=dict.get(i,x)
t+=r
return t
def numC(title): #PRBのポイント計算
dict={} #ココのブロックで辞書の中身を作る
f = open('PRCtitle.csv')#単語と出現頻度のファイル開く
data1 = f.readline() #各行を読み込む
while data1:#すべての行で繰り返す
lst=re.split('[,\n]', data1) #各行を,と\nで分割
dict[lst[0]]=float(lst[1]) #各単語=各頻度を辞書に保管
data1 = f.readline() #次の行を読み込む
f.close() #ファイルを閉じる
p=title.split() #入力したタイトルをリストに分割
#print(p)
t=0
for i in p:
#r=dict.get(i,-0.5)
r=dict.get(i,x)
t+=r
return t
def numD(title): #PRBのポイント計算
dict={} #ココのブロックで辞書の中身を作る
f = open('PRDtitle.csv')#単語と出現頻度のファイル開く
data1 = f.readline() #各行を読み込む
while data1:#すべての行で繰り返す
lst=re.split('[,\n]', data1) #各行を,と\nで分割
dict[lst[0]]=float(lst[1]) #各単語=各頻度を辞書に保管
data1 = f.readline() #次の行を読み込む
f.close() #ファイルを閉じる
p=title.split() #入力したタイトルをリストに分割
#print(p)
t=0
for i in p:
r=dict.get(i,x)
t+=r
return t
def numE(title): #PREのポイント計算
dict={} #ココのブロックで辞書の中身を作る
f = open('PREtitle.csv')#単語と出現頻度のファイル開く
data1 = f.readline() #各行を読み込む
while data1:#すべての行で繰り返す
lst=re.split('[,\n]', data1) #各行を,と\nで分割
dict[lst[0]]=float(lst[1]) #各単語=各頻度を辞書に保管
data1 = f.readline() #次の行を読み込む
f.close() #ファイルを閉じる
p=title.split()
#print(p)
t=0
for i in p:
r=dict.get(i,x)
t+=r
return t
def numL(title): #PRLのポイント計算
dict={} #ココのブロックで辞書の中身を作る
f = open('PRLtitle.csv')#単語と出現頻度のファイル開く
data1 = f.readline() #各行を読み込む
while data1:#すべての行で繰り返す
lst=re.split('[,\n]', data1) #各行を,と\nで分割
dict[lst[0]]=float(lst[1]) #各単語=各頻度を辞書に保管
data1 = f.readline() #次の行を読み込む
f.close() #ファイルを閉じる
p=title.split()
#print(p)
t=0
for i in p:
#r=dict.get(i,-0.40)
r=dict.get(i,x)
t+=r
return t
#テスト用のデータを読み込んで評価する
if __name__=="__main__":
lst=["L","A","B","C","D","E"] #タイトルのラベル
j=0 #ラベルの順番
total=0
for i in lst: #ラベルを順に調べる
title="PR"+i+"Title100.csv" #読み込むラベルのファイル
f = open(title) #ファイル開く
data=f.readline() #ファイルを各行読み込む=入力タイトル
q=0 #ラベルiの雑誌が他の雑誌よりもポイントが高い回数
while data: #すべての各行に対して繰り返す
word=data.lower() #タイトルをすべて小文字に変える
#print(word)
l=[numL(word), numA(word), numB(word), numC(word), numD(word), numE(word)] #あるタイトルの各雑誌ポイントのリスト
if l[j] >= max(l): #今のラベルiの雑誌のポイントが最大ならqに1加える
q+=1
data=f.readline() #つぎの行を読み込む
f.close() #ファイル閉じる
print("PR"+i+" point is " + str(q) +" /25 ") #ラベルiの雑誌がポイント最大だった回数(正解した回数のこと)
total+=q
j+=1 #つぎの雑誌の順番を指定するためラベルの順番を1増やす
print(str(total)+"/150") #各雑誌25タイトル合計150タイトルのうち正解タイトル数



コメント
コメントを投稿